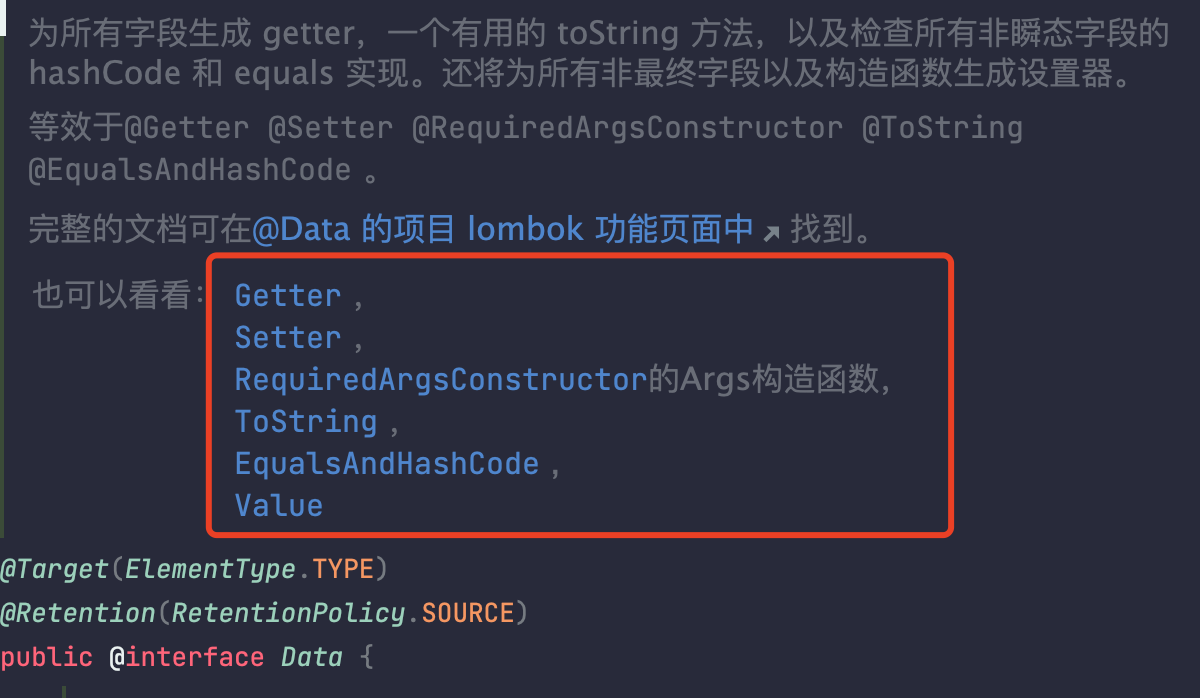
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import json
import logging
from datetime import datetime
class AuditLogger:
def __init__(self, log_file: str = '/var/log/audit.json'):
self.log_file = log_file
def log_event(self, event_type: str, user: str,
resource: str, action: str,
status: str, details: dict = None):
"""记录审计事件"""
event = {
'timestamp': datetime.utcnow().isoformat() + 'Z',
'event_type': event_type,
'user': user,
'resource': resource,
'action': action,
'status': status,
'details': details or {},
'source_ip': os.environ.get('REMOTE_ADDR', 'localhost')
}
with open(self.log_file, 'a') as f:
f.write(json.dumps(event) + '\n')
def log_api_call(self, service: str, endpoint: str,
params: dict, response_code: int):
"""记录API调用"""
safe_params = self._sanitize_dict(params)
self.log_event(
event_type='api_call',
user=os.getenv('USER', 'unknown'),
resource=f'{service}:{endpoint}',
action='call',
status='success' if 200 <= response_code < 300 else 'failed',
details={
'params': safe_params,
'response_code': response_code
}
)
audit = AuditLogger()
try:
result = process_file(filename)
audit.log_event(
'file_operation',
os.getenv('USER'),
filename,
'process',
'success',
{'size': len(result)}
)
except Exception as e:
audit.log_event(
'file_operation',
os.getenv('USER'),
filename,
'process',
'failed',
{'error': str(e)}
)
|