最近又在卷八股文,直呼卷不动了啊。这个行业啥时候才能不这么卷???
Java volatile 说起八股文,volatile绝对是个老八股,随便拉个人来都能说上两句,什么内存可见性、内存屏障、指令重排序。。。真搞不懂调包侠整这些玩意有啥用。
既然卷就卷到底,看看这玩意底层到底是在干啥。
字节码层 先定义一个Java类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Test private volatile int i; public void set (int i) this .i = i; } public int get () return this .i; } }
通过javac Test.java ,javap -c -p -v Test.class,得到可读的字节码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public class com .zhaojingzhou .Test minor version : 0 major version : 52 flags : ACC_PUBLIC , ACC_SUPER Constant pool : #1 = Methodref #4. #17 #2 = Fieldref #3. #18 #3 = Class #19 #4 = Class #20 #5 = Utf8 i #6 = Utf8 I #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 set #12 = Utf8 (I)V #13 = Utf8 get #14 = Utf8 ()I #15 = Utf8 SourceFile #16 = Utf8 Test.java #17 = NameAndType #7 :#8 #18 = NameAndType #5 :#6 #19 = Utf8 com/internet/zhaojingzhou/Test #20 = Utf8 java/lang/Object { private volatile int i; descriptor: I flags: ACC_PRIVATE, ACC_VOLATILE public com.zhaojingzhou.Test(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial #1 4 : return LineNumberTable: line 9 : 0 public void set (int ) descriptor: (I)V flags: ACC_PUBLIC Code: stack=2 , locals=2 , args_size=2 0 : aload_0 1 : iload_1 2 : putfield #2 5 : return LineNumberTable: line 14 : 0 line 15 : 5 public int get () descriptor: ()I flags: ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : getfield #2 4 : ireturn LineNumberTable: line 18 : 0 } SourceFile: "Test.java"
可以看到volatile关键字修饰的变量多了一个flag :ACC_VOLATILE
1 2 3 private volatile int i; descriptor: I flags: ACC_PRIVATE, ACC_VOLATILE
另外可以看到对于变量的读写指令是:
1 2 2 : putfield #2 1 : getfield #2
CPP层 根据我三脚猫的功夫,在源码中找到了这两个指令相关的内容,位于src/hotspot/share/interpreter/zero/bytecodeInterpreter.cpp
(这里说一下,我看的是jdk8的源码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 CASE (_getfield): CASE (_getstatic): { u2 index; ConstantPoolCacheEntry* cache; index = Bytes::get_native_u2 (pc+1 ); cache = cp->entry_at (index); if (cache->is_volatile ()) { if (support_IRIW_for_not_multiple_copy_atomic_cpu) { OrderAccess::fence (); } switch case btos: case ztos: SET_STACK_INT (obj->byte_field_acquire (field_offset), -1 ); break ; case ctos: SET_STACK_INT (obj->char_field_acquire (field_offset), -1 ); break ; case stos: SET_STACK_INT (obj->short_field_acquire (field_offset), -1 ); break ; case itos: SET_STACK_INT (obj->int_field_acquire (field_offset), -1 ); break ; case ftos: SET_STACK_FLOAT (obj->float_field_acquire (field_offset), -1 ); break ; case ltos: SET_STACK_LONG (obj->long_field_acquire (field_offset), 0 ); MORE_STACK (1 ); break ; case dtos: SET_STACK_DOUBLE (obj->double_field_acquire (field_offset), 0 ); MORE_STACK (1 ); break ; case atos: { oop val = obj->obj_field_acquire (field_offset); VERIFY_OOP (val); SET_STACK_OBJECT (val, -1 ); break ; } default : ShouldNotReachHere (); } }
可以看到,这里有几行这样的代码:
1 2 3 4 if (cache->is_volatile ()) { if (support_IRIW_for_not_multiple_copy_atomic_cpu) { OrderAccess::fence (); }
首先is_volatile判断是否volatile变量:
1 2 3 bool is_volatile () const return access_flags ().is_volatile (); }
好了,总算看到八股文里面说的内存屏障了OrderAccess::fence()。
咦,咋肥事,咋外面还套了个if。也就是说,并不是所有情况下都加了内存屏障。那support_IRIW_for_not_multiple_copy_atomic_cpu 这个玩意到底是个啥?从这个变量里似乎可以拆除两个东西,一个是multiple_copy_atomic,另一个是IRIW。关于这两个东西,在中文资源里能查找到的东西非常少,特别是IRIW。
MCA模型(multi-copy atomicity) 从为数不多的中文资源 中找到如下说法:
那怎么样才称为multi-copy atomicity呢?不正式但易于理解的说法是
When a write is visible to one thread other than its originating thread, it is visible to all other threads.
翻译过来就是:一个存储器写要么不被其他硬件线程看到,要是有一个看到了,那么就表示其他硬件线程都看到了。
这个定义其实和ARM文档里的multi-copy atomicity不一致,ARM文档里MCA的定义要更严格:发出存储器写的硬件线程自己也看不到这个写,除非其他硬件线程也看到了。这其实区别就在于是不是允许自己的写forward给自己的读。如果允许,就是通常的MCA定义,否则就是ARM文档里的定义。ARM文档把这种约束不甚严格的MCA称为“other-multicopy-atomic”。这也是困扰了我很久的一个问题。
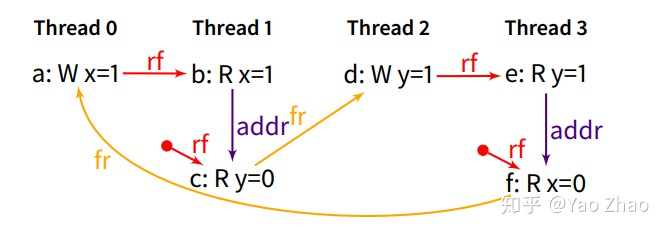
对于上图这个例子,MCA模型不可能最后Thread1和Thread3最后读到的y和x都是0的,因为这个结果表明Thread1看到a而没看到d;但Thread3看到d而没看到a,这是不符合MCA的定义的。而对于Non-MCA,上图的结果是可能的。
卧槽,上面说的不就是内存可见性的问题吗???
IRIW 那啥又是IRIW呢?“百度”出来的结果如下:
TOP5,唯一一个看着靠谱一点的结果,点进去一看:
这啥呀。。。。
但是也不是一点没用,至少知道了这个缩写代表的是Independent Reads, Independent Writes
但这玩意到底是个啥呢?最后我找到了一个论文 ,里面有一段内容:
里面说到了一个IRIW example:
有4个proc,0、1、2、3。proc0将x=1,proc1将y=1,proc2读到x=1,y=0,proc3读到y=1,x=0。
我寻思,IRIW难道就是MCA的反义?
后面又举了一个JMM的例子:
说的大概就是HotSpot之内的编译器会优化代码,将x=(r2==1)?y:1 优化为x=1,并优化了两个指令的位置,x=1跑r2=y前面去了。
IRIW又有独立指令重排的意思??
说实话看完我还是迷糊的,但是回到前面的那个条件:support_IRIW_for_not_multiple_copy_atomic_cpu,大概能明白意思了,应该是指支持IRIW而不是MCA的CPU就使用fence。
OrderAccess /src/hotspot/share/runtime/orderAccess.hpp中定义了一些内存屏障,具体的实现,不同的架构又不一样,linux_x86如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static inline void compiler_barrier () __asm__ volatile ("" : : : "memory" ) ; } inline void OrderAccess::loadload() { compiler_barrier(); } inline void OrderAccess::storestore() { compiler_barrier(); } inline void OrderAccess::loadstore() { compiler_barrier(); } inline void OrderAccess::storeload() { fence(); } inline void OrderAccess::acquire() { compiler_barrier(); } inline void OrderAccess::release() { compiler_barrier(); } inline void OrderAccess::fence() { #ifdef AMD64 __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc" , "memory" ) ;#else __asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc" , "memory" ) ; #endif compiler_barrier () ;}
其中lock; addl是关键 。
lock前缀是一个特殊的信号,执行过程如下:
对总线和缓存上锁。强制所有lock信号之前的指令,都在此之前被执行,并同步相关缓存。强制所有lock信号之后的指令,都在此之后被执行,并同步相关缓存。mfence的语义(当然,还有排他性的语义)。
与内存屏障相比,lock信号要额外对总线和缓存上锁,成本更高
而这里lock 后跟的是addl指令,对一个寄存器中的值加了0。然而通过lock信号的作用,实现了内存屏障的效果。
引用 https://zhuanlan.zhihu.com/p/150879932
http://www0.cs.ucl.ac.uk/staff/j.alglave/papers/ec209.pdf
https://www.cnblogs.com/sunddenly/articles/14829255.html
最后 卷得脑壳疼。。。